整体思维导图

RDD
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
五大属性
A list of partitionsA function for computing each splitA list of dependencies on other RDDsOptionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
- RDD 有分区
- RDD 要可以通过依赖关系和计算函数进行容错
- RDD 要针对数据本地性进行优化
- RDD 支持 MapReduce 形式的计算, 所以要能够对数据进行 Shuffled
对于 RDD 来说, 其中应该有什么内容呢? 如果站在 RDD 设计者的角度上, 这个类中, 至少需要什么属性?
Partition List分片列表, 记录 RDD 的分片, 可以在创建 RDD 的时候指定分区数目, 也可以通过算子来生成新的 RDD 从而改变分区数目Compute Function为了实现容错, 需要记录 RDD 之间转换所执行的计算函数RDD DependenciesRDD 之间的依赖关系, 要在 RDD 中记录其上级 RDD 是谁, 从而实现容错和计算Partitioner为了执行 Shuffled 操作, 必须要有一个函数用来计算数据应该发往哪个分区Preferred Location优先位置, 为了实现数据本地性操作, 从而移动计算而不是移动存储, 需要记录每个 RDD 分区最好应该放置在什么位置Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
| Transformation function | 解释 |
|---|---|
map(T ⇒ U) |
sc.parallelize(Seq(1, 2, 3)) .map( num => num * 10 ) .collect() 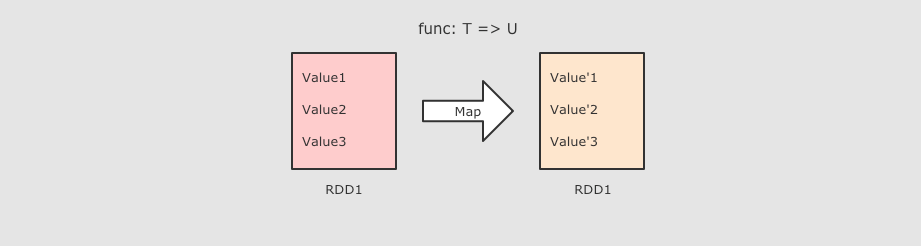 作用把 RDD 中的数据 一对一 的转为另一种形式签名 作用把 RDD 中的数据 一对一 的转为另一种形式签名def map[U: ClassTag](f: T ⇒ U): RDD[U]参数f → Map 算子是 原RDD → 新RDD 的过程, 传入函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据注意点Map 是一对一, 如果函数是 String → Array[String] 则新的 RDD 中每条数据就是一个数组 |