项目结构

蓝图
ORM数据库操作
1**、针对flask框架的web项目**
html文件写在templates文件夹里面
css文件还有静态资源(例如图片)放在static文件夹里面,直接访问 localhost:80/static/a.jpg
应用程序根目录是根据初始化app=Flask(name)的时候的代码在哪就决定了哪里是根目录
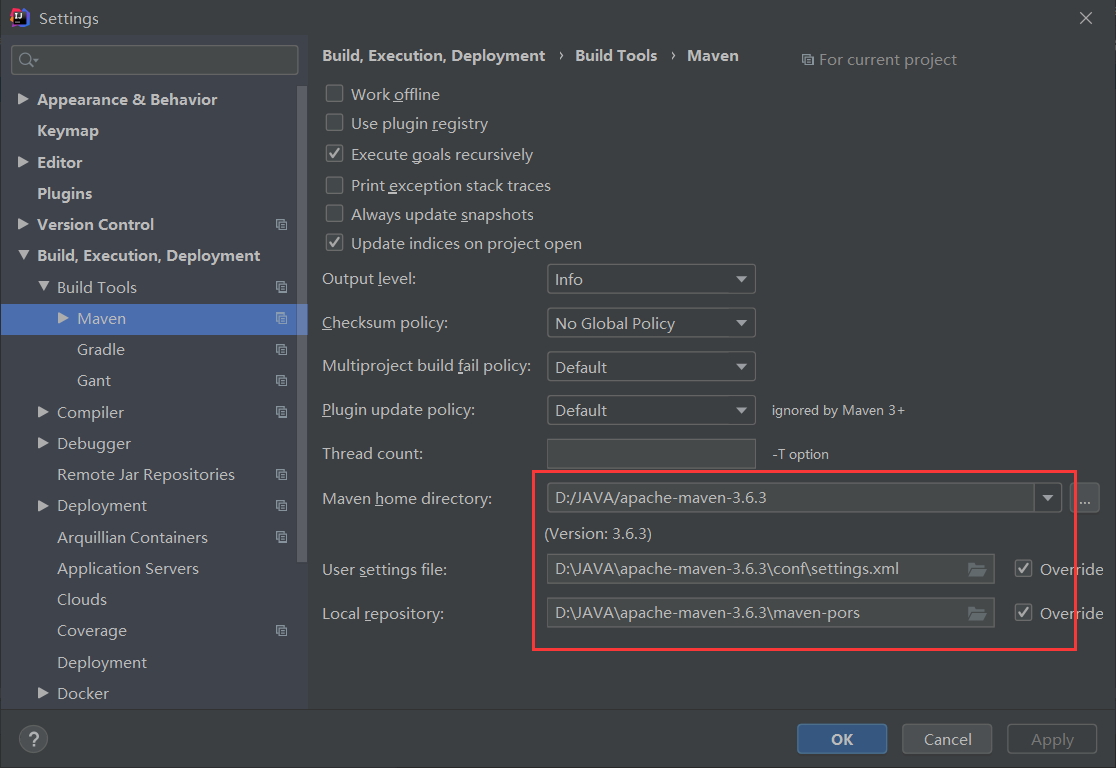
更改flask的默认设置静态资源位置:
static_folder
\1. app = Flask(name, static_folder=’hehe’)
\2. # http://127.0.0.1:5000/hehe/haha/a.png
\3. app = Flask(name, static_folder=”hehe/haha”)
\4. # http://127.0.0.1:5000/haha/a.png
static_url_path:
前端访问资源文件的前缀目录。默认是/static,就是前端必须这样访问:
我们改成 ‘’,就可以这样访问了:。就达到前端从根目录访问的目的了。
\1. app = Flask(name, static_folder=”hehe”,static_url_path=””)
\2. # http://127.0.0.1:5000/haha/a.png
2**、**url_for()
这个函数有很多的功能,是根据函数名反向生成路由url
\1. @app.route(‘/test’)
\2. def tt():
\3. return url_for(“tt”) # /test
3**、**redirect
功能就是跳转到指定的url,大部分情况下,我们都是和url_for一起使用的,例如:
\1. @app.route(‘/‘)
\2. def hello_world():
\3. return ‘Hello World’
\4.
\5.
\6. @app.route(‘//‘)
\7. def hello(name):
\8. if name == ‘Harp’:
\9. return ‘Hello %s’ % name
\10. else:
\11. return redirect(url_for(‘hello_world’))
在hello这个视图函数中,如果url传入的参数是Harp(即请求的网址是http://127.0.0.1:5000/Harp/),则返回'Hello Harp’,其他情况则重定向到hello_world这个视图函数对应的网址’/‘。
4**、获取input标签的用户名和密码**
方式一:**request.form[‘username’]**
下面指定的username和password是和上面的form中的name是一致的
方式二:**request.args[‘username’]**
如果要通过url来传送数据 , https://localhost:5000/login?username=jenrey
就要用下面这种方式获取参数值
5**、写cookie:**
6**、**@app.errorhandler(400)
我们不需要指定路由了, 只需要指定状态码,这样出现错误的时候,他就会自己响应到所对应的页面了。
errorhandler捕捉当前app或蓝图的状态码,并进行自定制处理
app_errorhandler捕捉全局状态码,并进行自定制异常处理
7**、产生依赖引用文档:**
C:\Users\Desktop\testflask>pip freeze > requirements.txt
指令执行完毕会产生一个文档,他会把我们用到的包列入到文档内
requirements这个文件名其实是python约定俗成的用法,当时我们使用这个文件名,pycharm会自动帮我们识别我们装了哪些包没装哪些包
8**、安装依赖引用文档的包:**
9**、**flask_script
先安装模块
pip install flask_script
flask_script 作用:可以通过命令行的形式来操作Flask,例如通过命令跑一个开发版本的服务器、设置数据库、定时任务等
代码中导入包:
或
直接把flask对象app传入进去
整体代码如下
python manage.py runserver #**启动服务**
flask-script官网:
具体的@manager.command用法看下面
10**、livereload:**
先安装模块:
pip install livereload
用**@manager.command**来,上面就传入了dev的参数
11**、**@app.template_filter() 把filter注册到模板
我们只要在函数上声明这个装饰器,就可以把这个filter注册到模板
自定义Markdown过滤器:
12**、@app.context_processor上下文处理器**
直接把方法注册到模板中。上下文处理器本身会返回一个字典的函数。其装饰的函数返回的内容对所有html模板都起作用。
13**、**@app.template_test 自定义测试函数
14**、**flash 消息闪现
导入flash
需要在配置文件中设置 SECRET_KEY 数值可以随意,其实就是秘钥,这样能保证数据的安全,因为我们的session是在客户端的,所以设置完SECRET_KEY后就可以通过系统自己的算法来进行验证数据安全的问题了。
这里看起来是个列表的形式,所以我们可以多次使用flash()
消息闪现的消息分类:
with和endwith是限制变量作用域的,errors只会在其之间有效果。原来我们不加with,变量的作用域是在block中的,加了之后就变成with中了。
15**、开启DEBUG调试模式**
有多种方法来开启debug模式:
1. 在app.run()中添加参数,变为app.run(debug=True);
2. 在run之前增加app.debug = True;
3. 新建config.py文件,在config文件中添加DEBUG = True,然后在程序中引入app.config.from_object(config);
4. 在run之前增加app.config[‘DEBUG’] = True;
建议使用第3种方式,其中还可以写入以下信息
\1. SECRET_KEY
\2. SQLALCHEMY_DB
\3. APP_ROOT
16**、**render_template 渲染静态的html文件,也能传递参数给html
作用:render_template不仅能渲染静态的html文件,也能传递参数给html
在templates文件夹建立一个html文件,内容随便写一点如下:
\1.
\2.
\3.
\4.
\5.
Index
\6.
\7.
\8.
This is index page
\9.
\10.
send_static_file**:**
我们可以使用Flask对象app的send_static_file方法,使视图函数返回一个静态的**html**文件,
但现在我们不使用这种方法,
而是使用flask的render_template函数,它功能更强大。
从flask中导入render_template,整体代码如下:
\1. from flask import Flask, render_template
\2. import config
\3.
\4. app = Flask(name)
\5. app.config.from_object(config)
\6.
\7.
\8. @app.route(‘/‘)
\9. def index():
\10. return render_template(‘index.html’)
\11.
\12. if name == ‘main‘:
\13. app.run()
render_template函数会自动在templates文件夹中找到对应的html,因此我们不用写完整的html文件路径。用浏览器访问’/‘这个地址,显示结果如下:
使一个html模板根据参数的不同显示不同的内容,这是因为flask使用了jinja2这个模板引擎。要使用模板,在**render_template参数中以key=value形式传入变量,在html中使用**来显示传入的变量,例如:
\1. # 视图函数
\2. @app.route(‘/‘)
\3. def index():
\4. return render_template(‘index.html’, contents=’This is index page’)
\5.
\6. # html
\7.
\8.
\9.
\10.
\11.
Index
\12.
\13.
\14.
\15.
\16.
浏览器显示的结果与上文是一样的。我们还可以直接把一个类的实例传递过去,并在模板中访问类的属性,例如假设一个类对象obj有a和b属性,关键部分的代码如下:
\1. # 视图函数中
\2. return render_template(‘index.html’, object=obj)
\3.
\4. …
\5. # html**中
\6.
a:
\7.
b:
传入一个字典也可以,并且在模板中既可以用dict[key],也可以用dict.key。
17**、ORM与**SQLAlchemy
以MySQL数据库为例,平时我们会用mysqldb(python 2)或者pymysql(python 3)去操作MySQL数据库,但这种方法也是需要自己编写SQL语句的。现在我们有了ORM模型,简单来说,ORM是把数据库中的表抽象成模型,表的列名对应模型的属性,这样我们可以调用类的属性或方法去获得数据库中的数据。例如假设MySQL数据库中有一张表名为table1,使用SELECT * FROM table1 WHERE id=1获取id为1的数据,如果将表table1映射成ORM模型Table,那么可以直接使用Table.query.filter(id=1),这样操作简单了很多,也很利于理解。
SQLAlchemy就是一个这样的ORM,我们可以直接安装flask_sqlalchemy来使用
在配置文件config.py中填写好数据库的连接信息:
\1. HOST = “127.0.0.1”
\2. PORT = “3306”
\3. DB = “harp”
\4. USER = “root”
\5. PASS = “Your Password”
\6. CHARSET = “utf8”
\7. DB_URI = “mysql+pymysql://{}:{}@{}:{}/{}?charset={}”.format(USER, PASS, HOST, PORT, DB, CHARSET)
\8. SQLALCHEMY_DATABASE_URI = DB_URI
SQLAlchemy**依赖mysqldb或者pymysql去连接数据库和执行SQL语句,**因为我们用的是python 3,所以需要在配置信息中指明使用pymysql,如果是python 2可以省略,默认是使用mysqldb。
建表
\1. from flask_sqlalchemy import SQLAlchemy
\2. from datetime import datetime
\3.
\4. import config
\5.
\6. app = Flask(name)
\7. app.config.from_object(config)
\8.
\9. db = SQLAlchemy(app)
\10.
\11.
\12. class Users(db.Model):
\13. tablename = ‘users_info’
\14. id = db.Column(db.Integer, primary_key=True, autoincrement=True)
\15. username = db.Column(db.String(32), nullable=False)
\16. password = db.Column(db.String(100), nullable=False)
\17. register_time = db.Column(db.DateTime, nullable=False, default=datetime.now())
\18.
\19.
\20. db.create_all()
tablename这个属性就是建表后,数据库生成的表名。primary_key=True说明该字段为主键,autoincrement=True代表自增长,nullable决定是否可为空,default代表默认值。最后用db.create_all()来实现创建。
进入数据库,输入desc user_info;,我们发现表已经建立好了,其结构图如下:
插入数据
\1. @app.route(‘/‘)
\2. def index():
\3. user = Users(username=’Harp’, password=’123456’)
\4. db.session.add(user)
\5. db.session.commit()
\6. return render_template(‘home.html’)
代码实例化一个Users的对象user,传入username和password,使用db.session.add(user)将其加入到数据库的session(可以理解为事务)中,然后使用db.session.commit()提交。我们运行程序,然后用浏览器访问,浏览器正常显示了结果,这时再看一眼数据库,发现这条数据已经写入到了数据库:
查询、修改数据
\1. @app.route(‘/‘)
\2. def index():
\3. user = Users.query.filter(Users.id == 1).first() #**查找
\4. print(user.username)
\5. user.username = ‘Harp1207’ #**修改
\6. db.session.commit() #**修改后需提交
\7. print(user.username)
\8. return render_template(‘home.html’)
外键关联
users_info表(Users模型)代码如下:
\1. class Users(db.Model):
\2. tablename = ‘users_info’
\3. id = db.Column(db.Integer, primary_key=True, autoincrement=True)
\4. username = db.Column(db.String(32), nullable=False)
\5. password = db.Column(db.String(100), nullable=False)
\6. register_time = db.Column(db.DateTime, nullable=False, default=datetime.now())
\7. # 我们新增了一个avatar_path字段来存用户头像图片文件的路径
\8. avatar_path = db.Column(db.String(256), nullable=False, default=’images/doraemon.jpg’)
questions_info表(Questions模型)代码如下:
\1. class Questions(db.Model):
\2. tablename = ‘questions_info’
\3. id = db.Column(db.Integer, primary_key=True, autoincrement=True)
\4. title = db.Column(db.String(100), nullable=False)
\5. content = db.Column(db.TEXT, nullable=False)
\6. author_id = db.Column(db.Integer, db.ForeignKey(‘users_info.id’))
\7. create_time = db.Column(db.DateTime, nullable=False, default=datetime.now())
\8.
\9. author = db.relationship(‘Users’, backref=db.backref(‘questions’, order_by=create_time.desc()))
这个表存储所有问题的标题、内容、创建时间、作者ID,作者ID通过外键与用户表的ID关联,方式也很简单,在db.Column中用db.ForeignKey(‘users_info.id’)作为参数即可。
再看最后一条语句:
author = db.relationship(‘Users’, backref=db.backref(‘questions’, order_by=create_time.desc()))
db.relationship会自动找到两个表的外键,建立Questions和Users的关系,此时对于任意一个Questions对象question,通过question.author就可获得这个question的作者对应的Users对象,例如获取id为1的问题的作者姓名:
\1. question = Questions.query.filter(Questions.id == 1).first()
\2. author_name = question.author.username
db.relationship的第二个参数backref=db.backref(‘questions’, order_by=create_time.desc())则建立了一个反向引用,这样我们不仅可以使用question.author,还可以使用author.questions获得一个作者所有的问题,并通过order_by=create_time.desc()按创建时间倒序排列(网页的内容按时间倒序排列),返回的是一个Questions对象的列表,可以遍历它获取每个对象,如获取作者Harp的所有问题的title:
\1. author = Users.query.filter(Users.username == ‘Harp’).first()
\2. for question in author.questions:
\3. print(question.title)
flask-migrate 数据库迁移(用途:更新表结构)
我们增加了两个模型Questions和Comments,并为Users增加了avatar_path这个字段,然后通过这段代码更新到数据库:
\1. with app.test_request_context():
\2. db.drop_all()
\3. db.create_all()
因为当使用过db.create_all()之后,再次直接使用db.create_all(),对模型的修改并不会更新到数据库,我们要使用db.drop_all()先把数据库中所有的表先删除掉,然后再db.create_all()一次。听上去是不是很麻烦?更糟糕的是,原先数据库的的数据也就没有了。所以我们不用这种简单粗暴的方式去更新数据库结构,而是借助flask-migrate这个专门用于迁移数据库的工具,它可以在保留数据库原始数据的情况下,完成模型的更新。此外,我们还将结合flask-script一起使用,简单来说flask-script让我们可以使用命令行去完成数据库迁移的操作。
在项目主文件夹下新建一个manage.py,代码如下:
\1. from flask_script import Manager
\2. from flask_migrate import Migrate, MigrateCommand
\3. from HarpQA import app, db
\4. from models import Users, Questions, Comments
\5.
\6. manager = Manager(app)
\7.
\8. migrate = Migrate(app, db)
\9.
\10. manager.add_command(‘db’, MigrateCommand)
\11.
\12.
\13. if name == ‘main‘:
\14. manager.run()
首先导入相关的类,注意模型要全部导入过来,即使代码中并没有显式地使用它们。然后传入app或db来构建Manager和Migrate两个类的实例,最后将MigrateCommand的命令加入到manager中。
此时我们假设要更新模型的结构,在models.py的User模型结尾添加一行代码test = db.Column(db.Integer),然后点击PyCharm下方的Terminal,自动进入到了虚拟环境的命令行中,输入python manage.py db init来初始化,这一步主要是建立数据库迁移相关的文件和文件夹,只是在第一次需要使用。接着依次使用python manage.py db migrate和python manage.py db upgrade,待运行完成,查看users_infor表的结构,结果如下:
可以看到test字段已经添加到表中了。
18**、**werkzeug.security 哈希与字符串的加密与解密
werkzeug.security中的
generate_password_hash**这个函数,将字符串变成hash值。**
password=generate_password_hash(password1)
werkzeug.security的
check_password_hash**方法,它能验证哈希值是否与原始的密码是匹配的**
check_password_hash(加密后的哈希, 需要对比的非哈希密码)
19**、**request.method == ‘GET’
\1. @app.route(‘/question/‘, methods=[‘GET’, ‘POST’])
\2. def question():
\3. if request.method == ‘GET’:
\4. return render_template(‘question.html’)
\5. else:
\6. question_title = request.form.get(‘question_title’)
\7. question_desc = request.form.get(‘question_desc’)
\8. author_id = Users.query.filter(Users.username == session.get(‘username’)).first().id
\9. new_question = Questions(title=question_title, content=question_desc, author_id=author_id)
\10. db.session.add(new_question)
\11. db.session.commit()
\12. return redirect(url_for(‘home’))
20**、**@app.before_request 钩子函数
@app.before_request这个钩子函数,看其名字就很好理解,是在**request**之前会自动运行的,我们在每次请求之前(或者说每次运行视图函数之前)。
例如通过钩子函数来得到当期登录用户的User对象(而不是仅仅是session中的username),然后在需要的地方使用它,代码如下:
\1. @app.before_request
\2. def my_before_request():
\3. username = session.get(‘username’)
\4. if username:
\5. g.user = Users.query.filter(Users.username == username).first()
这个钩子函数,从session中获取当前登陆的username,如果获取到了,再去检索Users模型,把返回的user对象存入到g对象中,在视图函数中我们就可以直接使用这个user对象的id/register_time等字段了。此时前面的视图函数中的
author_id = Users.query.filter(Users.username == session.get(‘username’)).first().id
可以修改成
author_id = g.user.id
g对象不能跨请求使用,因此在上下文管理器中用的是session,为什么这里又用了g对象呢?原因是现在有了钩子函数,每次请求都会执行钩子函数,向g对象中写入user,所以上下文管理器一直都能从g对象中取到user,不管这个g对象是属于哪次请求的。
21**、**request.files[name] 获取上传的文件
与获取POST数据类似(上传文件其实也是使用POST方法),在flask中使用request.files[name]获取上传的文件,其中name为对应input控件的name值(name=”avatar_upload”),然后使用文件的save方法即可保存。例如:
\1. @app.route(‘/user/avatar/‘, methods=[‘GET’, ‘POST’])
\2. def avatar():
\3. if request.method == ‘GET’:
\4. return render_template(‘avatar.html’)
\5. else:
\6. file = request.files[‘avatar_upload’]
\7. path = “D:\Flask\HarpQA\static\“
\8. file.save(path + file.filename)
\9. return ‘Saved’
注意save方法要加上具体的路径,默认不会保存到py文件所在的路径,而是系统的根目录,此时会提示Permission denied。
22**、**set_cookie 设置cookie
make_response方法生成一个response对象(这个对象有set_cookie方法,这也是Flask设置cookie的常规方法),并为其设置cookie,set_cookie第一个参数’sid’是key,第二个参数是value(session id),之后返回response对象。当请求是GET时候,首先就会使用request.cookies.get(‘sid’)去获取cookie中的session id
23**、**make_response
make_response(),相当于DJango中的HttpResponse。
· 返回内容
\1. from flask import make_response
\2.
\3. @app.route(‘/makeresponse/‘)
\4. def make_response_function():
\5. response = make_response(‘
羞羞哒
‘)
\6. return response, 404
· 返回页面
\1. from flask import make_response
\2.
\3. @app.route(‘/makeresponse/‘)
\4. def make_response_function():
\5. temp = render_template(‘hello.html’)
\6. response = make_response(temp)
\7. return response
>>>注意:make_response 想要返回页面,不能直接写做:make_response(‘hello.html’),必须用render_template(‘hello.html’)形式。
· 返回状态码
>>>**方式一:在make_response()中传入状态码**
\1. from flask import make_response
\2.
\3. @app.route(‘/makeresponse/‘)
\4. def make_response_function():
\5. temp = render_template(‘hello.html’)
\6. response = make_response(temp, 200)
\7. return response
>>>**方式二:直接return状态码**
\1. from flask import make_response
\2.
\3. @app.route(‘/makeresponse/‘)
\4. def make_response_function():
\5. temp = render_template(‘hello.html’)
\6. response = make_response(temp)
\7. return response, 200
24**、redirect **跳转
flask中的 redirect 相当于 DJango中的 HttpResponseRedirect。
1.**参数是url形式**
\1. from flask import redirect
\2.
\3. @app.route(‘/redirect/‘)
\4. def make_redirect():
\5. return redirect(‘/hello/index/‘)
2.**参数是 name.name 形式**
url_for 相当于reverse,name.name 相当于django中的namespace:name,第一个name是初始化蓝图时的参数名,第二个name是函数名
\1. from flask import redirect
\2.
\3. @blue.route(‘/redirect/‘)
\4. def make_redirect():
\5. return redirect(url_for(‘first.index’))
25**、request的属性**
\1. #代码示例,仅仅是为了测试request**的属性值
\2. @app.route(‘/login’, methods = [‘GET’,’POST’])
\3. def login():
\4. if request.method == ‘POST’:
\5. if request.form[‘username’] == request.form[‘password’]:
\6. return ‘TRUE’
\7. else:
\8. #当form**中的两个字段内容不一致时,返回我们所需要的测试信息
\9. return str(request.headers) #**需要替换的部分
\10. else:
\11. return render_template(‘login.html’)
1**、method:请求的方法**
return request.method #POST
2**、form:返回form的内容**
return json.dumps(request.form) #{“username”: “123”, “password”: “1234”}
3**、args和values:args返回请求中的参数,values返回请求中的参数和form**
\1. return json.dumps(request.args) #url:http://192.168.1.183:5000/login?a=1&b=2**、返回值:**{"a": “1”, “b”: “2”}
\2. return str(request.values) #CombinedMultiDict([ImmutableMultiDict([(‘a’, ‘1’), (‘b’, ‘2’)]), ImmutableMultiDict([(‘username’, ‘123’), (‘password’, ‘1234’)])])
4**、cookies:cookies信息**
return json.dumps(request.cookies) #cookies**信息
5**、headers:请求headers信息,返回的结果是个list**
\1. return str(request.headers) #headers**信息
\2. request.headers.get(‘User-Agent’) #获取User-Agent**信息
6**、url、path、script_root、base_url、url_root:看结果比较直观**
\1. return ‘url: %s , script_root: %s , path: %s , base_url: %s , url_root : %s’ % (request.url,request.script_root, request.path,request.base_url,request.url_root)
\2. #url: http://192.168.1.183:5000/testrequest?a&b , script_root: , path: /testrequest , base_url: http://192.168.1.183:5000/testrequest , url_root : http://192.168.1.183:5000/
7**、date、files:date是请求的数据,files随请求上传的文件**
\1. @app.route(‘/upload’,methods=[‘GET’,’POST’])
\2. def upload():
\3. if request.method == ‘POST’:
\4. f = request.files[‘file’]
\5. filename = secure_filename(f.filename)
\6. #f.save(os.path.join(‘app/static’,filename))
\7. f.save(‘app/static/‘+str(filename))
\8. return ‘ok’
\9. else:
\10. return render_template(‘upload.html’)
\11.
\12. #html
\13.
\14.
\15.
\16.
\20.
\21.
26**、jsonify flask提供的json格式数据处理方法**
python的flask框架为用户提供了直接返回包含json格式数据响应的方法,即jsonify
在flask中使用jsonify和json.dumps的区别
27**、g对象**
1.在flask中,有一个专门用来存储用户信息的g对象,g的全称的为global。
2.g对象在一次请求中的所有的代码的地方,都是可以使用的。
flask之g对象
28**、Flask-HTTPAuth **扩展 HTTP认证
安装:
pip install flask-httpauth
Flask-HTTPAuth提供了几种不同的Auth方法,比如HTTPBasicAuth**,HTTPTokenAuth,MultiAuth和**HTTPDigestAuth。
· HTTPBasicAuth**:**基础认证
创建扩展对象实例
\1. from flask import Flask
\2. from flask_httpauth import HTTPBasicAuth
\3.
\4. app = Flask(name)
\5. auth = HTTPBasicAuth()
注意,初始化实例时不需要传入app对象,也不需要调用”auth.init_app(app)”注入应用对象。
案例:用户名及密码验证
我们所要做的,就是实现一个根据用户名获取密码的回调函数:
@auth.get_password 的使用(明文密码有效)
\1. users = [
\2. {‘username’: ‘Tom’, ‘password’: ‘111111’},
\3. {‘username’: ‘Michael’, ‘password’: ‘123456’}
\4. ]
\5.
\6. @auth.get_password
\7. def get_password(username):
\8. for user in users:
\9. if user[‘username’] == username:
\10. return user[‘password’]
\11. return None
回调函数”get_password()”由装饰器”@auth.get_password”修饰。在函数里,我们根据传入的用户名,返回其密码;如果用户不存在,则返回空。
@auth.login_required 的使用
接下来,我们就可以在任一视图函数上,加上”@auth.login_required”装饰器,来表示该视图需要认证:
\1. @app.route(‘/‘)
\2. @auth.login_required
\3. def index():
\4. return “Hello, %s!” % auth.username()
启动该应用,当你在浏览器里打开”http://localhost:5000/”,你会发现浏览器跳出了下面的登录框,输入正确的用户名密码(比如上例中的Tom:111111)后,”Hello Tom!”的字样才会显示出来。
进入浏览器调试,发现认证并没有启用Cookie,而是在请求头中加上了加密后的认证字段:
Authorization: Basic TWljaGFlbDoxMjM0NTY=
这就是”HTTPBasicAuth”认证的功能,你也可以用Curl命令来测试:
curl -u Tom:111111 -i -X GET http://localhost:5000/
@auth.verify_password 的使用(非明文密码有效)
上例中”@auth.get_password”**回调只对明文的密码有效,但是大部分情况,我们的密码都是经过加密后才保存的,这时候,我们要使用另一个回调函数”@auth.verify_password”。在演示代码之前,先要介绍Werkzeug**库里提供的两个方法:
· generate_password_hash: 对于给定的字符串,生成其加盐的哈希值
· check_password_hash: 验证传入的哈希值及明文字符串是否相符
这两个方法都在”werkzeug.security”包下。现在,我们要利用这两个方法,来实现加密后的用户名密码验证:
\1. from werkzeug.security import generate_password_hash, check_password_hash
\2.
\3. users = [
\4. {‘username’: ‘Tom’, ‘password’: generate_password_hash(‘111111’)},
\5. {‘username’: ‘Michael’, ‘password’: generate_password_hash(‘123456’)}
\6. ]
\7.
\8. @auth.verify_password
\9. def verify_password(username, password):
\10. for user in users:
\11. if user[‘username’] == username:
\12. if check_password_hash(user[‘password’], password):
\13. return True
\14. return False
在”@auth.verify_password”所修饰的回调函数里,我们验证传入的用户名密码,如果正确的话返回True,否则就返回False。
错误处理
在之前的例子中,如果未认证成功,服务端会返回401状态码及”Unauthorized Access”文本信息。你可以重写错误处理方法,并用”@auth.error_handler”装饰器来修饰它:
\1. from flask import make_response, jsonify
\2.
\3. @auth.error_handler
\4. def unauthorized():
\5. return make_response(jsonify({‘error’: ‘Unauthorized access’}), 401)
有了上面的”unauthorized()”方法后,如果认证未成功,服务端返回401状态码,并返回JSON信息”{‘error’: ‘Unauthorized access’}”。
· HTTPTokenAuth**:Token认证**
在对HTTP形式的API发请求时,大部分情况我们不是通过用户名密码做验证,而是通过一个令牌,也就是Token来做验证。此时,我们就要请出Flask-HTTPAuth扩展中的HTTPTokenAuth对象。
同HTTPBasicAuth类似,它也提供”login_required”装饰器来认证视图函数,”error_handler”装饰器来处理错误。
@auth.verify_token 的使用
区别是,它没有”verify_password”装饰器,相应的,它提供了”verify_token”装饰器来验证令牌。我们来看下代码,为了简化,我们将Token与用户的关系保存在一个字典中:
\1. from flask import Flask, g
\2. from flask_httpauth import HTTPTokenAuth
\3.
\4. app = Flask(name)
\5. auth = HTTPTokenAuth(scheme=’Bearer’)
\6.
\7. tokens = {
\8. “secret-token-1”: “John”,
\9. “secret-token-2”: “Susan”
\10. }
\11.
\12. @auth.verify_token
\13. def verify_token(token):
\14. g.user = None
\15. if token in tokens:
\16. g.user = tokens[token]
\17. return True
\18. return False
\19.
\20. @app.route(‘/‘)
\21. @auth.login_required
\22. def index():
\23. return “Hello, %s!” % g.user
可以看到,在”verify_token()”方法里,我们验证传入的Token是否合法,是的话返回True,否则返回False。另外,我们通过Token获取了用户信息,并保存在全局变量g中,这样视图中可以获取它。注意,在第一节的例子中,我们使用了”auth.username()”来获取用户名,但这里不支持。
初始化HTTPTokenAuth对象时,我们传入了”scheme=’Bearer’”。这个scheme,就是我们在发送请求时,在HTTP头”Authorization”中要用的scheme字段。
启动上面的代码,并用Curl命令来测试它:
curl -X GET -H “Authorization: Bearer secret-token-1” http://localhost:5000/
HTTP头信息”Authorization: Bearer secret-token-1″,”Bearer”就是指定的scheme,”secret-token-1″就是待验证的Token。在上例中,”secret-token-1″对应着用户名”John”,所以Token验证成功,Curl命令会返回响应内容”Hello, John!”。
使用**itsdangerous**库来管理令牌
itsdangerous库提供了对信息加签名(Signature)的功能,我们可以通过它来生成并验证令牌。使用前,先记得安装”pip install itsdangerous”。现在,让我们先来产生令牌,并打印出来看看:
\1. from itsdangerous import TimedJSONWebSignatureSerializer as Serializer
\2.
\3. app = Flask(name)
\4. app.config[‘SECRET_KEY’] = ‘secret key here’
\5. serializer = Serializer(app.config[‘SECRET_KEY’], expires_in=1800)
\6.
\7. users = [‘John’, ‘Susan’]
\8. for user in users:
\9. token = serializer.dumps({‘username’: user})
\10. print(‘Token for {}: {}\n’.format(user, token))
这里实例化了一个针对JSON的签名序列化对象serializer,它是有时效性的,30分钟后序列化后的签名即会失效。让我们运行下程序,在控制台上,会看到类似下面的内容:
\1. Token for John: eyJhbGciOiJIUzI1NiIsImV4cCI6MTQ2MzUzMzY4MCwiaWF0IjoxNDYzNTMxODgwfQ.eyJ1c2VybmFtZSI6IkpvaG4ifQ.ox-64Jbd2ngjQMV198nHYUsJ639KIZS6RJl48tC7-DU
\2.
\3. Token for Susan: eyJhbGciOiJIUzI1NiIsImV4cCI6MTQ2MzUzMzY4MCwiaWF0IjoxNDYzNTMxODgwfQ.eyJ1c2VybmFtZSI6IlN1c2FuIn0.lRx6Z4YZMmjCmga7gs84KB44UIadHYRnhOr7b4AAKwo
接下来,改写”verify_token()”方法:
\1. @auth.verify_token
\2. def verify_token(token):
\3. g.user = None
\4. try:
\5. data = serializer.loads(token)
\6. except:
\7. return False
\8. if ‘username’ in data:
\9. g.user = data[‘username’]
\10. return True
\11. return False
我们通过序列化对象的”load()”方法,将签名反序列化为JSON对象,也就是Python里的字典。然后获取字典中的用户名,如果成功则返回True,否则返回False。这样,就实现了加密后的令牌认证了,让我们用Curl测试一下,还记得刚才控制台上打印出的令牌吗?
curl -X GET -H “Authorization: Bearer eyJhbGciOiJIUzI1NiIsImV4cCI6MTQ2MzUzMzY4MCwiaWF0IjoxNDYzNTMxODgwfQ.eyJ1c2VybmFtZSI6IkpvaG4ifQ.ox-64Jbd2ngjQMV198nHYUsJ639KIZS6RJl48tC7-DU” http://localhost:5000/
· MultiAuth**:** 多重认证
Flask-HTTPAuth扩展还支持几种不同认证的组合,比如上面我们介绍了HTTPBasicAuth和HTTPTokenAuth,我们可以将两者组合在一起,其中任意一个认证通过,即可以访问应用视图。实现起来也很简单,只需将不同的认证实例化为不同的对象,并将其传入MultiAuth对象即可。大体代码如下:
\1. from flask_httpauth import HTTPBasicAuth, HTTPTokenAuth, MultiAuth
\2.
\3. …
\4.
\5. basic_auth = HTTPBasicAuth()
\6. token_auth = HTTPTokenAuth(scheme=’Bearer’)
\7. multi_auth = MultiAuth(basic_auth, token_auth)
\8.
\9. …
\10.
\11. @basic_auth.verify_password
\12. …
\13.
\14. @token_auth.verify_token
\15. …
\16.
\17. @basic_auth.error_handler
\18. …
\19.
\20. @token_auth.error_handler
\21. …
\22.
\23. @app.route(‘/‘)
\24. @multi_auth.login_required
\25. def index():
\26. return ‘Hello, %s!’ % g.user
这里,每个认证都有自己的验证和错误处理函数,不过在视图上,我们使用”@multi_auth.login_required”来实现多重认证。大家可以使用Curl命令试验下。
· HTTPDigestAuth**:**
暂无举例
详情请点击Flask 扩展 HTTP认证–flask-httpAuth
29**、return **返回问题
例如下面的代码返回的是空的,因为浏览器会解析html标签,但是我们标签里面没有内容所以无任何显示
如果想当做普通字符串打印出来就需要返回的content-type=text/plain,如下图所示,需要导入flask的make_response
现在我们在做一个有意思的测试(转发)
可以看到直接转发到了bing的网站
上面还有一种简单的写法就是如下图所示:
上面我们用逗号分隔的形式其实是我们的flask的元组,当你返回为一个元组的时候flask内部还是会把它自动变成一个response对象的。在返回回去。
改成下面这样,就是返回json格式的数据了,其实这就是web返回的本质,返回的本质都是都是字符串,只不过控制的因素在这个context-type,他控制了我们的客户端在接收到我们的返回的时候要怎么样的去解释我们的返回内容。
30**、flask-login **的使用
当用户登录成功之后我们要产生一个票据,并且把这个票据写入cookie中,我们不仅负责写入票据还要负责读取票据,并且要管理这个票据,整个的登陆机制是非常繁琐的,所以我们自己去用cookie实现这一整套的管理机制是非常不明智的,很幸运的是flask给我们提供了插件flask-login,可以完全用这个插件来管理登陆信息。
导入插件