- pwd 显示文件系统中到达当前目录的路径。从某种意义上说,那个目录是在树中
所处的位置。实际上该目录是一些字节的集合,而这个集合存储在磁盘上的某个
位置,该位置能以柱面、磁头、扇区和字节的方式定位。有办法将当前工作目录转
换成这些硬件位置吗?
看一下所使用的系统中的一个硬盘。找出它有多少个分区,确定每个分区的1 -节
点的个数和数据块的个数。查看本机所有磁盘 fdisk -l
lsblk
看一下所使用的系统中的一个硬盘。找出它有多少个分区,确定每个分区的1 -节
点的个数和数据块的个数。
查看本机所有磁盘 fdisk -l
lsblk
maven 打包jar_Maven一定要会的这几个知识!_weixin_39716044的博客-CSDN博客
Maven是什么?
Maven,这个单词来源于犹太语,意味着知识的积累。最初在Jakarta Turbine 项目中用来简化构造项目流程。最终,形成基于Java项目的构建和管理的工具。
安装与配置
安装比较简单,官网下载,配置环境即可。这里推荐一下,安装之后配置仓库镜像,可以加快访问速度。
编辑 settings.xml,在 之前添加
使用其他工具创建项目也如出一辙。
Maven项目结构
Maven 基本概念
POM(Project Object Model)
POM的全称是Project Object Model,用通俗点的话说就是对要构建的项目进行建模,将要构建的项目看成是一个对象(Object)。
我们可以用我们熟悉的一个Java代码来描述一下这个对象。
Lifecycle(生命周期)
在Maven中一次构建过程就是一个Lifecycle,这个Lifecycle分为多个阶段,每个阶段叫做Phase。有三种构建的生命周期,分别是 default、 clean、 site。default用于部署项目, clean用于清理项目,而 site用于创建项目文档。
defaultLifecycle包含如下Phase:
validate:校验项目和一些必要信息是可用的
compile:编译项目源码
test:执行源码的单元测试模块
package:将项目打包,比如打包成jar文件
verify:对集成测试的结果进行检查,以确保满足质量标准
install:将软件包安装到本地仓库中
deploy:将软件包部署到远程仓库
maven 常用命令介绍
清理项目产生的临时文件,一般是模块下的target目录
mvn clean
项目打包工具,会在模块下的target目录生成jar或者war等文件
mvn package
测试命令或者执行src/test/java下面的测试用例
mvn test
模块安装命令,将打包的jar或者war文件复制到本地仓库,使用-Dmaven.test.skip=true 跳过测试
mvn install
发布命令,将打包的文件发布到maven仓库
mvn deploy
maven 多个命令同时使用
mvn clean package-U -Dmaven.test.skip=true-P test
Phase和Goals
Lifecycle只规定了项目构建的流程,即先执行 validate,再 compile等一系列Phase,但并没有定义每一个Phase具体做什么。这里Phase的作用类似于Java中的接口,而Phase的具体实现在Goals里面。
一个Phase必须绑定一个或多个Goals,才能执行具体的构建流程。为了让用户不用任何配置就能使用Maven项目,Maven默认为一些核心生命周期的Phase绑定了Goals。
如果需要自定义绑定,可以在 pom.xml文件中配置。
Maven核心概念
Maven坐标
Maven坐标主要是为了标识项目的唯一性。由下面几个属性组成:
groupId:组织或者组织的项目名称
artifactId:项目中的具体模块
version:项目版本
packaging:项目打包方式
classifier:用于区分从同一POM构建的具有不同内容的构件
Maven仓库
存储管理构件(JAR、WAR等)的地方。
一般分为以下三类:
本地仓库:默认是 ~/.m2/repository 目录,可在配置文件中配置其他目录
私服:内网的Maven仓库
中央仓库:Maven社区提供的仓库,包含大量的常用库
Maven依赖
在 pom.xml配置项目依赖,比如
junitjunit4.12test
scope用来控制依赖和编译、测试、运行的classpath的关系。有下面三种关系:
compile:默认编译依赖范围。对于编译、测试、运行三种classpath都有效
test:测试依赖范围。只对测试classpath有效
provided:已提供依赖范围。编译、测试classpath有效,对于运行无效。
runtime:运行时提供
test:仅用于测试,且不可传递
system:类似于provided,但必须显示提供JAR
import:仅在 dependencyManagement下支持。
传递依赖
Maven是通过传递依赖解析JAR包依赖,比如我项目中引入junit,在解析我的项目的时候,不仅仅仅有junit,还有junit依赖的JAR包。
包冲突时怎么产生的?
假设 A->B->C->D1, E->F->D2,D1、D2 分别为 D 的不同版本。
如果 pom.xml 文件中引入了 A 和 E 之后,按照 Maven 传递依赖原则,工程内需要引入的实际 JAR 包将会有:A B C D1 和 E F D2,因此 D1、D2 将会产生包冲突。
如何解决包冲突?
Maven解析 pom.xml的时候,同一个JAR包只会保留一个。
对于包冲突,Maven处理策略:
最短路径优先:Maven面对 D1 D2,会选择最短路径的那个,即D2。因为,E->F->D2 比 A->B->C->D1 路径短。
最先声明优先:如果路径一样,就选择最先声明的JAR包。
如何移除依赖?
Maven继承
继承为了消除重复。可以把很多相同的配置提取出来。
子模块通过 parent标签配置,继承父模块属性。父模块通过 dependencyManagement标签进行管理。
多模块版本号可以通过maven命令操作,在项目根目录执行
设置新版本号
mvn versions:set-DnewVersion=0.0.2-SNAPSHOT
回滚设置新版本号操作
mvn versions:revert
提交设置新版本号操作
mvn versions:commit
1 | 1、常量和变量:尽量使用常量,可以避免很多问题 |
 函数基本语法
函数基本语法
高阶函数
1、作为值的函数
函数就像和数字、字符串一样,可以将函数传递给一个方法,如List的map方法,可以接收一个函数
1 | val func:Int => String = (num:Int) => "*" * num |
2、匿名函数
没有赋值给变量的函数就是匿名函数
1 | (1 to 10).map(num => "*" * num) |
3、柯里化
将原先接受多个参数的方法转换为多个只有一个参数的参数列表的过程。
1 | def add(x:Int)(y:Int) = { |
相当于
1 | def add(x:Int) = { |
4、闭包
闭包其实就是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
1 | val y = 10 |
样例类和普通类的区别:
1 | case class People(name:String,age:Int) |
1、数组:定长数组(Array)、变长数据(ArrayBuffer)
2、列表:不可变列表(List)、可变列表(ListBuffer)
3、Set:
4、Map
不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable
普通方法或者函数中的参数可以通过 implicit 关键字声明为隐式参数,调用该方法时,
就可以传入该参数,编译器会在相应的作用域寻找符合条件的隐式值。
1)说明
(1) 同一个作用域中,相同类型的隐式值只能有一个
(2) 编译器按照隐式参数的类型去寻找对应类型的隐式值,与隐式值的名称无关。
(3) 隐式参数优先于默认参数
1 | object TTT { |
在 Scala2.10 后提供了隐式类,可以使用 implicit 声明类,隐式类的非常强大,同样可
以扩展类的功能,在集合中隐式类会发挥重要的作用。
1)隐式类说明
(1) 其所带的构造参数有且只能有一个
(2) 隐式类必须被定义在“类”或“伴生对象”或“包对象”里,即隐式类不能是顶
级的。
1 | object TTT { |
模式匹配:
match 对应 Java 里的 switch,但是写在选择器表达式之后。即: 选择器 match {备选项}。
match 表达式通过以代码编写的先后次序尝试每个模式来完成计算,只要发现有一个匹配的case,剩下的case不会继续匹配。
1 | def matchTest(x: Any): Any = x match { |
1 | class MyList[**+T**]{ //协变 |
协变:Son 是 Father 的子类,则 MyList[Son] 也作为 MyList[Father]的“子类”。
逆变:Son 是 Father 的子类,则 MyList[Son]作为 MyList[Father]的“父类”。
不变:Son 是 Father 的子类,则 MyList[Father]与 MyList[Son]“无父子关系”。 3)实操
泛型的上下限的作用是对传入的泛型进行限定。
1 | Class PersonList[T <: Person]{} //泛型上限 |
Maven 构建生命周期就是 Maven 将一个整体任务划分为一个个的阶段,类似于流程图,按顺序依次执行。也可以指定该任务执行到中间的某个阶段结束。
Maven 的内部有三个构建生命周期,分别是 clean, default, site。其中 default 生命周期的核心阶段如下所示:
default lifecycle
执行 mvn install 命令,将完成 validate, compile, test, package, verify, install 阶段,并将 package 生成的包发布到本地仓库中。其中某些带有连字符的阶段不能通过 shell 命令单独指定。例如:(pre-, post-, or process-*)
1 | mvn install |
执行 mvn clean deploy 命令,首先完成的 clean lifecycle,将以前构建的文件清理,然后再执行 default lifecycle 的 validate, compile, test, package, verify, insstall, deploy 阶段,将 package 阶段创建的包发布到远程仓库中。
1 | mvn clean deploy |
如上所述,Maven 将构建过程定义为 default lifecycle,并将 default lifecycle 划分为一个个的阶段 phase,这一系列 phase 仅仅是规定执行顺序,至于每个阶段做什么工作?由谁来做?答案就在 插件(plugins) 中。
Maven 对工程的所有操作实实在在的都是由 插件 来完成的。一个插件可以支持多种功能,称之为目标(goal),例如:compiler 插件有两个目标:compile 和 testCompile,分别实现编译源代码 和 编译测试代码。
如何将插件与 Maven 的构建生命周期绑定在一起呢?通过将插件的目标(goal)与 build lifecycle 中 phase 绑定到一起,这样,当要执行某个 phase 时,就调用插件来完成绑定的目标。
如下图所示:从图中可以看出,每一个阶段可以绑定0 个 或 多个目标,每个插件可以提供 1 个或多个目标。
build lifecycle & plugin goal
在 pom.xml 文件中,packaging 类型支持 jar, war, ear, pom 等多种类型,不同的 packaging 类型会使得不同的 phase 绑定不同的 plugin goal。下面是 packaging 类型为 jar 时,phase 与 plugin goal 的映射关系。
| 阶段 | 目标 |
|---|---|
| process-resources | resources:resources |
| compile | compiler:compile |
| process-test-resources | resources:testResources |
| test-compile | compiler:testCompile |
| test | surefire:test |
| package | jar:jar |
| install | install:install |
| deploy | deploy:deploy |
在 pom.xml 文件中,
例如:将插件 modello-maven-plugin 的 java 目标绑定到 generate-sources 阶段。
1 | <plugin> |
你可以能会疑问,默认的 pom.xml 文件并没有配置各种 plugin,但是也能正常构建工程?答案是 Maven 自己默认指定了 plugin。
下面是一个没有配置任何 plugin 的 pom.xml,执行 mvn install 的输出日志,从日志中可以看到 一系列的 插件(plugin):版本号:目标(phase),例如 maven-resources-plugin:2.6:resources (default-resources),maven-compiler-plugin:3.1:compile (default-compile) ,maven-resources-plugin:2.6:testResources (default-testResources),maven-compiler-plugin:3.1:testCompile (default-testCompile),maven-surefire-plugin:2.12.4:test (default-test),maven-jar-plugin:2.4:jar (default-jar) ,maven-install-plugin:2.4:install (default-install),
1 | [INFO] Scanning for projects... |
| phase | function |
|---|---|
| pre-clean execute | execute processes needed prior to the actual project cleaning |
| clean | remove all files generated by the previous build |
| post-clean | execute processes needed to finalize the project cleaning |
| phase | function |
|---|---|
| validate | validate the project is correct and all necessary information is available. |
| initialize | initialize build state, e.g. set properties or create directories. |
| generate-sources | generate any source code for inclusion in compilation. |
| process-sources | process the source code, for example to filter any values. |
| generate-resources | generate resources for inclusion in the package. |
| process-resources | copy and process the resources into the destination directory, ready for packaging. |
| compile | compile the source code of the project. |
| process-classes | post-process the generated files from compilation, for example to do bytecode enhancement on Java classes. |
| generate-test-sources | generate any test source code for inclusion in compilation. |
| process-test-sources | process the test source code, for example to filter any values. |
| generate-test-resources | create resources for testing. |
| process-test-resources | copy and process the resources into the test destination directory. |
| test-compile | compile the test source code into the test destination directory |
| process-test-classes | post-process the generated files from test compilation, for example to do bytecode enhancement on Java classes. For Maven 2.0.5 and above. |
| test | run tests using a suitable unit testing framework. These tests should not require the code be packaged or deployed. |
| prepare-package | perform any operations necessary to prepare a package before the actual packaging. This often results in an unpacked, processed version of the package. (Maven 2.1 and above) |
| package | take the compiled code and package it in its distributable format, such as a JAR. |
| pre-integration-test perform | actions required before integration tests are executed. This may involve things such as setting up the required environment. |
| integration-test | process and deploy the package if necessary into an environment where integration tests can be run. |
| post-integration-test | perform actions required after integration tests have been executed. This may including cleaning up the environment. |
| verify | run any checks to verify the package is valid and meets quality criteria. |
| install | install the package into the local repository, for use as a dependency in other projects locally. |
| deploy | done in an integration or release environment, copies the final package to the remote repository for sharing with other developers and projects. |
| phase | function |
|---|---|
| pre-site | execute processes needed prior to the actual project site generation |
| site | generate the project’s site documentation |
| post-site | execute processes needed to finalize the site generation, and to prepare for site deployment |
| site-deploy | deploy the generated site documentation to the specified web server |
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
A list of partitionsA function for computing each splitA list of dependencies on other RDDsOptionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)对于 RDD 来说, 其中应该有什么内容呢? 如果站在 RDD 设计者的角度上, 这个类中, 至少需要什么属性?
Partition List 分片列表, 记录 RDD 的分片, 可以在创建 RDD 的时候指定分区数目, 也可以通过算子来生成新的 RDD 从而改变分区数目
Compute Function 为了实现容错, 需要记录 RDD 之间转换所执行的计算函数
RDD Dependencies RDD 之间的依赖关系, 要在 RDD 中记录其上级 RDD 是谁, 从而实现容错和计算
Partitioner 为了执行 Shuffled 操作, 必须要有一个函数用来计算数据应该发往哪个分区
Preferred Location 优先位置, 为了实现数据本地性操作, 从而移动计算而不是移动存储, 需要记录每个 RDD 分区最好应该放置在什么位置
Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用 presist 方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
| Transformation function | 解释 |
|---|---|
map(T ⇒ U) |
sc.parallelize(Seq(1, 2, 3)) .map( num => num * 10 ) .collect() 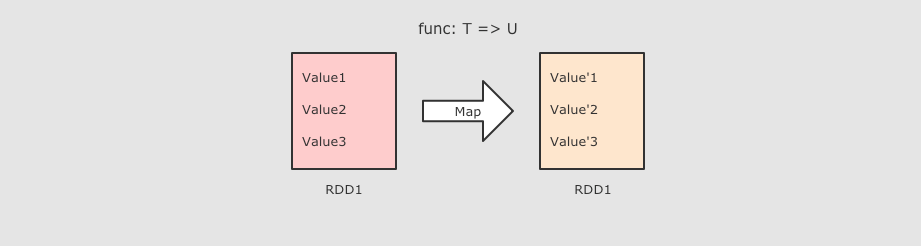 作用把 RDD 中的数据 一对一 的转为另一种形式签名 作用把 RDD 中的数据 一对一 的转为另一种形式签名def map[U: ClassTag](f: T ⇒ U): RDD[U]参数f → Map 算子是 原RDD → 新RDD 的过程, 传入函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据注意点Map 是一对一, 如果函数是 String → Array[String] 则新的 RDD 中每条数据就是一个数组 |
替换方式以及文件可以参考Repo@Loyalsoldier/v2ray-rules-dat。
具体:设置-路由设置-勾选启用高级路由功能。
首先复制以下一种配置内容:
带广告屏蔽的:
1 | [ |
不带广告屏蔽
1 | [ |
接着在路由设置页面设置:高级功能-添加规则集-导入规则-从剪贴板中导入规则,别名自己设置一个。
在参数设置-V2rayN设置中勾选
添加方式与条目3相同
1 | [ |

自定义域名,规则集里面编辑规则
代理就在proxy添加
直连就在direct添加
只是添加域名的话就是domain:xxxxxx
正则具体语法可以参考官网